- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
语音转写产品正深度融入智能办公系统,形成 “语音 - 文字 - 数据” 的协同闭环。在协同办公平台中,转写功能可与会议系统直接对接,会议发起时自动开启转写,参会者可实时标注个人负责事项,转写文档自动关联参会人账号,会后系统根据标注生成个人任务清单;与客户关系管理(CRM)系统集成时,客户沟通录音转写后,系统自动提取客户需求、意向产品等关键信息,更新至客户档案,同时触发后续跟进提醒;与文档协作工具结合,多人语音讨论内容转写后,可直接生成协作文档,支持多人在线编辑、评论,避免信息传递偏差,明显提升团队协作效率与信息流转速度。教育领域用语音转写记录授课内容,生成的文字笔记可辅助学生课后复习。南京全数字语音转写作用

语音转写产品具备极强的设备适配性,支持多终端无缝衔接使用,满足用户在不同场景下的设备切换需求,这一优点大幅提升了使用灵活性。在设备覆盖上,可完美适配电脑(Windows/Mac)、手机(iOS/Android)、平板、智能录音笔等多种设备,用户在电脑端开启会议转写后,外出途中可通过手机端实时查看进度,回到办公室再用平板端编辑文档,数据实时同步不丢失;在设备联动上,支持与智能硬件深度协作,例如连接智能麦克风后,可增强语音采集效果,减少环境噪音干扰,连接打印机可直接导出转写文档并打印,无需额外传输文件;针对特殊设备,如工业级录音设备、车载系统,也能通过定制化接口实现适配,确保在户外作业、车载办公等场景下正常使用,真正实现 “随时随地,想用就用”。南京自动记录语音转写同时翻译语音转写的定时销毁功能可设置数据留存期限,到期自动彻底删除,避免泄露。

语音转写产品遵循清晰的版本更新与功能迭代逻辑,确保产品持续满足用户需求。版本更新分为 “常规更新” 与 “重大更新”:常规更新每月 1-2 次,主要修复已知 bug、优化现有功能(如提升特定口音转写准确率、优化文档导出速度),更新包体积小,不影响用户正常使用;重大更新每季度 1 次,推出全新重心功能(如新增情感识别、多语种互转),同时对界面进行优化升级,提升用户体验。功能迭代逻辑以用户需求为重心:先通过用户反馈渠道、市场调研收集需求,按 “高频需求优先、重要需求重点投入” 原则排序;再由技术团队评估可行性,制定迭代方案;开发完成后,先在小范围用户群体中进行测试,收集使用反馈并调整;较后正式上线,同时提供新功能使用教程,确保用户能快速掌握。
尽管智能语音转写取得了明显进步,但仍然存在一些技术局限亟待解决.一方面,在复杂的环境中,如存在大量背景噪音的情况下,语音转写的准确率会受到一定影响.这是因为背景噪音会干扰语音信号的提取和分析,使得系统难以准确识别语音内容.另一方面,对于一些非常专业、生僻的词汇和领域特定术语,语音转写系统可能无法准确识别.针对这些问题,研究人员正在不断探索新的技术和方法.例如,研发更先进的降噪算法来提高在复杂环境中的识别能力,以及加强特定领域的语料库建设,使系统能够更好地理解和处理专业词汇.未来,智能语音转写技术将朝着更加精细、高效、智能化的方向发展,为用户提供更好的服务.法律庭审场景中,语音转写标注发言主体,文档可联动庭审录像定位关键片段。

语音转写产品针对物流行业高频场景,开发流程化应用功能提升效率。在仓储分拣场景,支持 “语音指令转写 + 任务分配”,分拣员通过语音上报货物信息(如 “A 区货架 3 层,快递单号 12345”),产品实时转写并同步至仓储管理系统,自动生成分拣任务清单,避免手动录入错误;在运输调度场景,将司机与调度中心的通话实时转写,自动提取运输路线、货物状态(如 “货物破损,位置在高速 G65 段”)等关键信息,生成调度记录并同步至物流跟踪系统,便于客户实时查看货物情况;在签收确认场景,支持 “客户语音确认转写 + 电子存档”,客户签收时的语音确认(如 “货物已收到,无问题”)可转写为文字并生成电子凭证,与签收时间、地点关联存档,减少纸质单据管理成本,推动物流流程数字化升级。利用语音转写功能,教育工作者可以将教学讲解语音转写成文字辅助教学。上海多语言识别语音转写软件系统
语音转写的用户社群定期分享使用技巧,产品团队收集反馈优化功能迭代方向。南京全数字语音转写作用
无纸化语音转写是现代科技的一项不错成果.在信息炸的现在,传统的纸质记录方式面临着诸多挑战,如空间占用、查找不便等.而语音转写技术让一切变得更为高效.它能够将口述内容快速、准确地转化为电子文字.无论是在会议场景中,各种观点和决策迅速被语音捕捉并转写,还是在个人学习记录方面,如语言学习的口语练习转化成文字复习资料,都极大地提高了效率.而且语音转写系统不断学习优化,对于不同口音、语速都有了更强的适应性,减少了转换过程中的错误,为使用者提供了可靠、便捷的无纸化记录手段.南京全数字语音转写作用

智能语音转写,简单来说,是将语音信号转化为文字信息的技术.其背后蕴含着复杂而精妙的原理.它的运行基础是声学模型和语言模型.声学模型负责分析语音的声学特征,例如音素的发音方式、音高、音色等.语言模型则像是一本巨大的语料库,包含着丰富的语言知识和语法规则.当语音输入进来时,系统首先对声学特征进行提取,然后与声学模型进行比对,初步确定可能的语音内容.接着,语言模型对这些初步结果进行评估,根据语法和语义的合理性进行筛选和调整,较终输出准确的文字.例如,当听到“现在天气很好”这句话时,系统会通过声学分析识别出各个音素,再由语言模型判断出这是符合正常语义的表达,从而完成转写.语音转写的新手引导提供动画演示...
- 广州自动记录语音转写同时转写 2026-03-14
- 广州国产化语音转写系统 2026-03-13
- 北京多语种识别语音转写售后维护 2026-03-13
- 长沙全数字语音转写报价 2026-03-13
- 广州语音转写系统 2026-03-13
- 广州文字识别语音转写软件系统 2026-03-13
- 广州全数字语音转写软件系统 2026-03-13
- 广州多语种识别语音转写故障排除 2026-03-13
- 长沙智能语音转写报价 2026-03-13
- 上海AI智能语音转写报价 2026-03-13

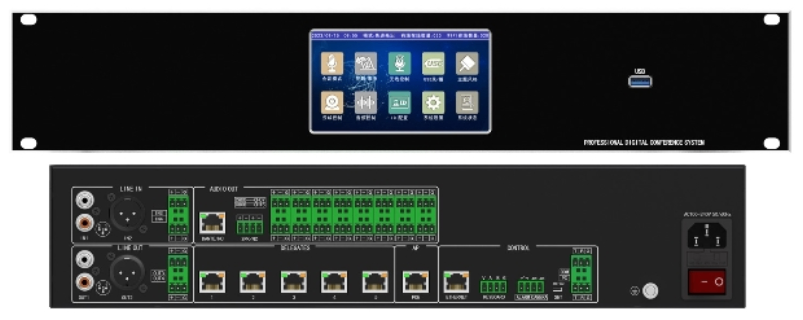
- 南京实时语音转写哪家好 2026-03-13
- 南京国产化语音转写哪家好 2026-03-12
- 上海法院语音转写哪家好 2026-03-12
- 长沙会议纪要语音转写软件系统 2026-03-12
- 北京会议纪要语音转写好用吗 2026-03-12
- 长沙智能翻译语音转写怎么样 2026-03-12


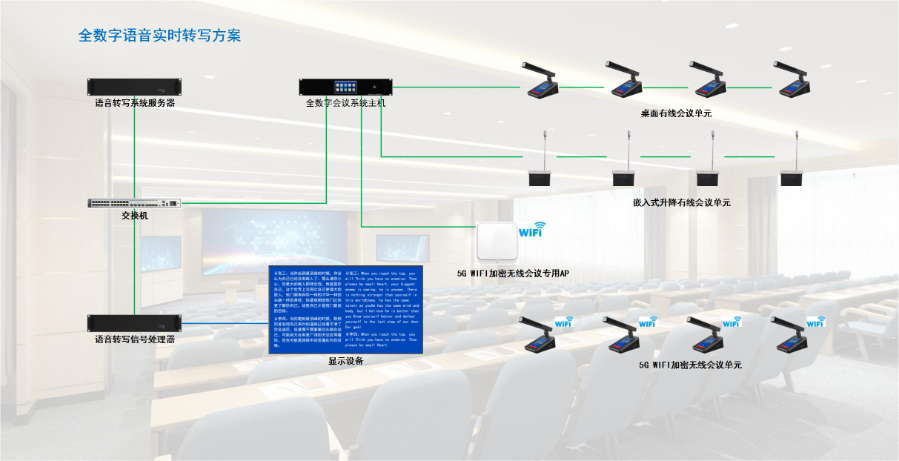

- 广州语音转写系统 03-13
- 广州文字识别语音转写软件系统 03-13
- 广州全数字语音转写软件系统 03-13
- 广州多语种识别语音转写故障排除 03-13
- 长沙智能语音转写报价 03-13
- 上海AI智能语音转写报价 03-13
- 智能翻译语音转写售后 03-13
- 南京角色分离语音转写售后维护 03-13
- 智能语音转写云平台 03-13
- 广州自动翻译语音转写云平台 03-13