- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
语音转写产品正与 AI 写作工具深度协同,形成 “语音输入 - 文字转写 - AI 优化” 的内容创作闭环。在自媒体创作中,用户通过语音口述文案思路,转写产品将语音转化为文字初稿后,AI 写作工具可自动优化语句逻辑、补充细节内容,还能根据需求生成不同风格文案(如幽默风、专业风);在公文写作场景,转写后的会议讨论要点经 AI 工具处理,可自动按照公文格式(如通知、报告)梳理结构,生成规范的公文初稿,减少格式调整时间;在学术写作中,转写的研究思路、实验记录经 AI 工具分析,能辅助生成文献综述框架、标注潜在研究漏洞,为科研人员提供写作支持。二者协同既保留用户原始创作意图,又提升内容质量与创作效率。直播场景中,语音转写能实时生成字幕,支持中英双语切换,适配跨境观众。北京多角色语音转写字幕

语音转写产品的精细性依赖三大重心技术:声学模型、语言模型与语音活动检测(VAD)。声学模型负责将语音信号转化为音素序列,通过海量语音数据训练,能区分不同口音、语速及背景噪音;语言模型基于语法规则与语义逻辑,优化文字组合合理性,例如避免 “形式” 误写为 “形势”;VAD 技术则可自动识别语音片段与静音时段,剔除无效信息,提升转写效率。部分不错产品还融入实时降噪、多 speaker 分离技术,在嘈杂会议或多人对话场景中,仍能保持清晰转写效果,技术迭代方向正朝着 “低资源语种适配”“跨模态信息融合” 持续推进。北京智能翻译语音转写字幕语音转写软件可对语音中的模糊词汇进行智能猜测和转写。

为解决偏远地区、移动场景等低带宽环境下的使用痛点,语音转写产品研发低带宽适配技术。技术层面,采用 “轻量化语音压缩算法”,将语音数据压缩至原体积的 30% 以下,在网速低于 1Mbps 的环境中,仍能实现实时转写,且不影响识别准确率;同时推出 “分段传输 + 断点续传” 功能,网络不稳定时,系统将语音数据分段传输,断网后自动保存已传输片段,网络恢复后继续传输未完成部分,避免因断网导致转写中断;此外,针对无网络场景,优化离线模型体积,将重心离线转写模型压缩至 500MB 以内,支持在手机、平板等移动设备本地安装,满足户外勘探、乡村调研等无网场景的语音记录需求,打破网络环境对产品使用的限制。
医疗领域对语音转写产品的准确性与安全性要求极高,相关应用需遵循严格规范并具备专业功能。在应用规范上,产品需符合医疗数据安全法规,确保患者病历、诊疗对话等敏感信息不泄露,同时转写内容需具备可追溯性,关联诊疗时间、医护人员信息,满足医疗文档合规要求;功能层面,医疗特用语音转写产品内置海量医学术语词典,可精细识别 “心肌梗死”“头孢菌素” 等专业词汇,支持病历模板调用,医护人员通过语音描述患者症状、诊疗方案,系统自动按病历格式转写生成文档,减少手工录入工作量。此外,部分产品还支持与电子病历系统对接,转写完成的病历可直接导入系统,提升医疗文书撰写效率与准确性。借助语音转写功能,医生可以将患者的口述病情快速转写成病历。
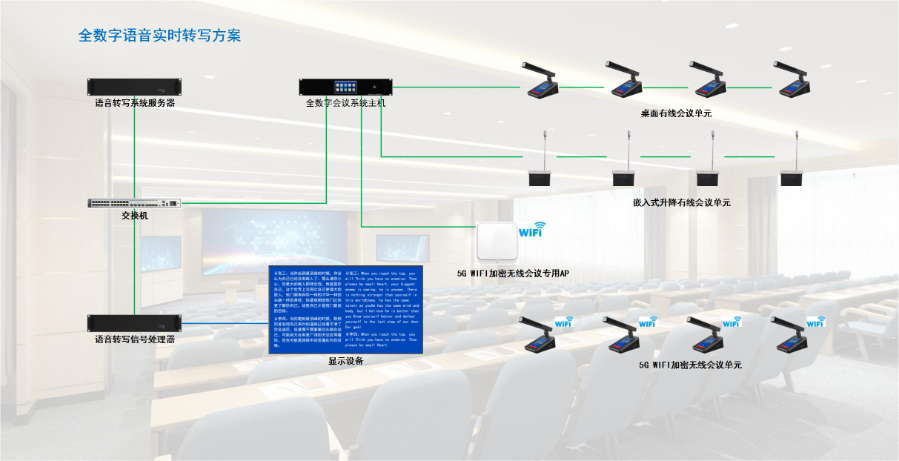
针对方言与不同口音的识别难题,语音转写产品研发了专项适配技术。技术层面,通过构建多语种、多方言语音数据库,涵盖粤语、四川话、东北话等主流方言及各地方口音普通话,采用迁移学习算法,让模型在通用语音识别基础上,快速适配特定方言与口音特征;同时,引入口音自适应训练功能,用户可上传少量带口音的语音样本,模型通过学习调整识别参数,提升个人语音转写准确率。部分产品还推出方言转写专项版本,针对特定地区用户需求,优化方言词汇、语法识别逻辑,例如识别粤语中的 “唔该”“系啊” 等常用词汇,解决方言沟通场景下的转写痛点,拓宽产品适用人群范围。语音转写的轻量化离线模型体积小,500MB以内可安装在移动设备使用。北京音频转文字语音转写同时转写
语音转写工具可对语音中的口语化表达进行规范化处理,使文字更通顺。北京多角色语音转写字幕
为满足用户多样化音频处理需求,语音转写产品提升多格式音频兼容性,覆盖主流与特殊音频格式。在常见格式支持上,可直接处理 MP3、WAV、AAC、M4A 等 10 余种主流音频格式,无需用户额外转换;针对专业场景,新增对无损音频格式(如 FLAC、ALAC)、语音备忘录格式(如 iPhone 的 m4a、安卓的 amr)的支持,适配录音笔、专业录音设备录制的音频文件;对于老旧音频文件(如磁带转录的 wav、早期录音笔的 mp2),产品内置 “音频修复模块”,可自动降噪、修复音频失真,提升转写准确率;此外,支持批量导入多格式音频文件,系统按格式自动分类处理,生成统一格式的转写文档,减少用户格式转换的繁琐操作,提升音频处理效率。北京多角色语音转写字幕
语音转写产品针对物流行业高频场景,开发流程化应用功能提升效率。在仓储分拣场景,支持 “语音指令转写 + 任务分配”,分拣员通过语音上报货物信息(如 “A 区货架 3 层,快递单号 12345”),产品实时转写并同步至仓储管理系统,自动生成分拣任务清单,避免手动录入错误;在运输调度场景,将司机与调度中心的通话实时转写,自动提取运输路线、货物状态(如 “货物破损,位置在高速 G65 段”)等关键信息,生成调度记录并同步至物流跟踪系统,便于客户实时查看货物情况;在签收确认场景,支持 “客户语音确认转写 + 电子存档”,客户签收时的语音确认(如 “货物已收到,无问题”)可转写为文字并生成电子凭证,与签...
- 广州语音转写系统 2026-03-13
- 广州全数字语音转写软件系统 2026-03-13
- 广州多语种识别语音转写故障排除 2026-03-13
- 上海AI智能语音转写报价 2026-03-13
- 智能翻译语音转写售后 2026-03-13
- 南京角色分离语音转写售后维护 2026-03-13
- 智能语音转写云平台 2026-03-13
- 广州自动翻译语音转写云平台 2026-03-13
- 南京实时语音转写哪家好 2026-03-13
- 南京国产化语音转写哪家好 2026-03-12



- 自动翻译语音转写云平台 2026-03-12
- 上海会议纪要语音转写软件 2026-03-12
- 北京会议纪要语音转写价格 2026-03-12
- 庭审语音转写有什么功能 2026-03-12
- 上海全数字语音转写字幕 2026-03-12
- 语音转写报价 2026-03-12





- 智能翻译语音转写售后 03-13
- 南京角色分离语音转写售后维护 03-13
- 智能语音转写云平台 03-13
- 广州自动翻译语音转写云平台 03-13
- 南京实时语音转写哪家好 03-13
- 南京国产化语音转写哪家好 03-12
- 上海法院语音转写哪家好 03-12
- 长沙会议纪要语音转写软件系统 03-12
- 北京会议纪要语音转写好用吗 03-12
- 长沙智能翻译语音转写怎么样 03-12