- 品牌
- 珍岛,臻成
- 服务项目
- 软件服务
- 服务地区
- 全国
- 服务周期
- 一年
- 适用对象
- 中小企业
- 提供发票
- 是
- 营业执照
- 是
- 专业资格证
- 否
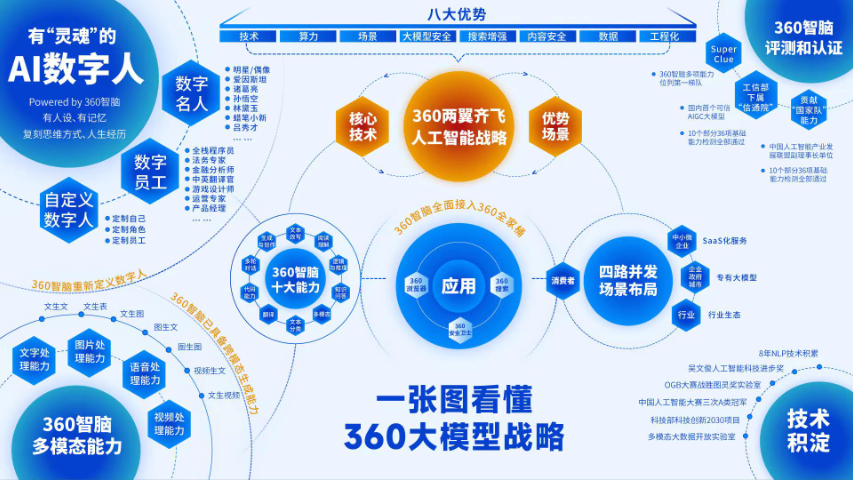
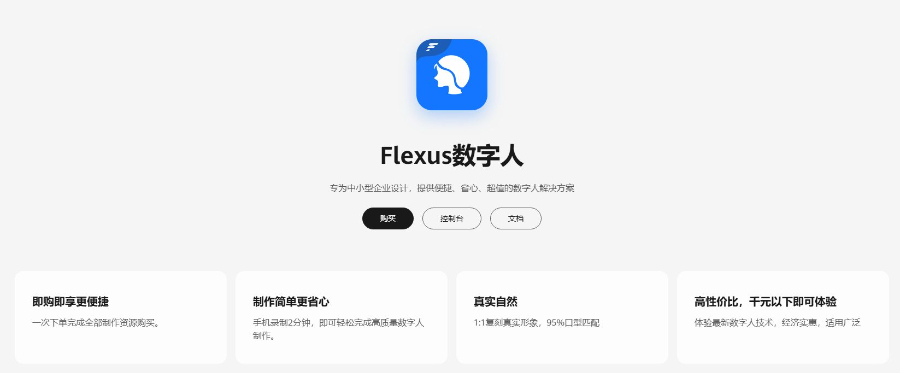
华为数字人依托华为自研的AI大模型与多模态交互技术,实现了从“形似”到“神似”的跨越式发展。其深度集成的自然语言处理系统不仅能准确理解复杂语境中的隐含需求,还能结合先进的计算机视觉技术实时捕捉用户的微表情、肢体动作与语音语调变化,让人机对话不仅流畅自然,更饱含细腻的情感温度。在各类智能服务场景中,它可根据用户的年龄、身份及沟通场景灵活切换沟通风格,无论是面对专业技术人员时的严谨解答,还是面向普通消费者时的亲切产品介绍,都能应对自如。这种高度拟人化的特性,彻底打破了传统人机交互的冰冷壁垒,让数字服务充满人文关怀,为用户带来更具沉浸感与信任感的交互体验,成为高效连接数字世界与现实生活的重要桥梁,推动智能服务迈入全新阶段。 华为云Flexus数字人专为中小企业设计,千元以下即可体验,支持多种行业场景。短视频创作华为数字人的模式

华为数字人技术通过自主研发的机器学习服务,实现了从文本到视频的智能生成。用户只需提供简单的文字内容,即可快速生成具备真人形象、表情和声音的播报视频。该技术突破了传统数字人制作的高门槛,支持多语种播报,包括中文女声、英文男女声等,并允许自定义背景和 LOGO。目前,其应用已覆盖新闻、教育、医疗等多个领域,例如在新闻播报中实现 24 小时不间断更新,为企业节省人力成本的同时提升信息传播效率。个人创作者通过 Flexus 数字人可快速构建个性化 IP。平台支持多语言克隆和情感化互动,用户只需简单操作即可生成专业级内容。例如,某知识博主利用数字人分身实现了多平台内容同步更新,粉丝增长 300%。这种技术为个人品牌提供了低成本、高效率的内容生产方式,推动了自媒体行业的专业化发展。华为云华为数字人的成本虚拟主持人 “云笙” 实现多语言同传与实时互动,展区导览数字人覆盖计算、交通等领域,日均服务数千人次。

华为数字人的技术基础华为数字人基于华为云强大的算力底座和盘古大模型,结合多模态AI技术,实现了从文本、语音到图像的多模态融合。这种技术架构使得数字人不仅能够理解自然语言,还能通过语音和表情进行自然交互,为用户带来更加丰富和真实的体。数字人生成的高效性华为云MetaStudio平台提供了一站式的数字人生成服务,用户只需提供3~5分钟的视频和100句语音数据,即可在短时间内生成高度逼真的数字人。这种高效的生成方式有效降低了数字人的制作门槛,使得更多企业和个人能够快速应用。
华为数字人并非一个简单的预渲染3D动画或静态形象,它是基于人工智能、计算机图形学、多模态交互等多种前沿技术创造的,具备高度拟人化外观、自然语言理解和实时交互能力的数字智能体。其重要价值在于“交互”而非“展示”。与传统的虚拟主播或游戏角色不同,华为数字人拥有精细的骨骼绑定、肌肉模拟和微表情系统,能够实现逼真的口型、眼神、手势和肢体动作,并与语音内容完美同步。更重要的是,它内置了强大的自然语言处理引擎,能够理解用户的意图,并在特定知识领域内进行有逻辑、有情感的对话。这意味着它可以从一个展示品,升级为一个真正的虚拟员工、顾问、助手或伙伴,应用于客服、导览、培训、直播等需要复杂沟通的场景,是实现人机自然交互的关键一步。平台以 95% 口型匹配准确率、1:1 形象复刻及千元级成本,打破传统数字人技术壁垒,助力中小企业数字化升级。

华为数字人支持多种语言,并通过语音大模型实现了语言的泛化能力。这种多语言支持使得数字人能够在全球范围内应用.数字人的口型匹配技术华为数字人通过自研的高精度口型驱动技术,实现了口型与语音的高度匹配,准确率超过95%。这种技术使得数字人的表现更加自然。 数字人的视频制作功能华为云MetaStudio提供了强大的数字人视频制作功能,用户可以通过简单的操作生成高质量的视频内容。这种功能在广告、教育和娱乐等领域具有重要应用。华为数字人视频制作:提供一站式视频制作平台,支持4K分辨率输出,满足多种场景需求。华为云华为数字人的成本
华为数字人保障数据安全,在金融场景中,安全高效完成身份核验。短视频创作华为数字人的模式
强大的算力支持与模型基础华为云数字人依托华为云底层海量的算力基础设施和自研的盘古数字人大模型,具备强大的技术基础。这种算力支持使得数字人在生产效率、口型匹配度、表情动作自然性以及智能化等方面表现出色。多模态融合能力华为云MetaStudio数字人通过多模态学习,整合文本、图像、语音等多种技术,使模型能够自动发现不同模态之间的关联和互补信息,从而实现更普遍的、准确的理解和生成。高效的内容生成与交付华为云数字人能够快速生成高质量的数字内容。例如,通过MetaStudio平台,只需提供3-5分钟的视频和100句语音数据,即可在短时间内完成数字人分身的训练和交付。自然语言处理与交互能力数字人通过自然语言处理技术,能够理解用户的意图并进行流畅的对话。这种能力使得数字人可以应用于多种场景,如智能客服、直播互动等。高精度的口型匹配与表情驱动华为云数字人采用生成对抗网络和多模态输入技术,实现了高精度的口型驱动,口型匹配准确率超过95%,交互时延低至2秒左右。短视频创作华为数字人的模式
- 陕西个性化定制华为数字人的策略 2026-02-09
- 5G 赋能华为数字人的定位 2026-02-09
- 陕西华为数字人的用户评价 2026-02-07
- 企业定制华为数字人的策略 2026-02-07
- 数字人定制华为数字人哪家好 2026-02-05
- 个人定制华为数字人建模效果 2026-02-04
- 定制华为数字人的技巧 2026-02-04
- 电商华为数字人的效果展示 2026-02-04
- 陕西个人定制华为数字人的内容 2026-02-03
- 榆林企业定制华为数字人 2026-02-03
- 陕西企业定制华为数字人的内容 2026-02-03
- 个人定制华为数字人的技巧 2026-02-03